
Lightweight Models for Edge Object Detection
Edge object detection is transforming industries by enabling real-time AI processing directly on local devices like IoT sensors and embedded systems. This eliminates the need for cloud reliance, reduces latency, and enhances privacy. Lightweight models, such as YOLO variants and hybrid architectures, optimize resource use and deliver fast, accurate results on hardware like Raspberry Pi and NVIDIA Jetson Nano. Key advancements include reduced model parameters, efficient deployment frameworks, and specialized designs for edge applications.
Key Takeaways:
- Why It Matters: Real-time performance is vital for autonomous vehicles, public safety, and industrial monitoring.
- Challenges: Edge devices face limits in processing power, energy efficiency, and memory bandwidth.
- Solutions: Lightweight models like YOLOv7-Tiny and MobileViT balance speed and accuracy, with techniques like quantization and pruning enhancing efficiency.
- Applications: Widely used in transportation, public safety, healthcare, and industrial predictive maintenance.
Edge AI is projected to grow significantly, with the market expected to reach $206 billion by 2032. This shift towards localized, efficient AI processing is reshaping how industries approach safety, efficiency, and innovation.
Build an Object Detector Running on a Microcontroller Using Edge Impulse FOMO and Azure IoT
sbb-itb-fd1fcab
YOLO Variants Optimized for Edge Computing
The YOLO (You Only Look Once) series has evolved to include several versions tailored for edge devices. These variants address the constraints of hardware like Raspberry Pi and NVIDIA Jetson by incorporating specific architectural enhancements. The focus is on balancing performance and resource efficiency, making them ideal for edge deployment.
YOLOv7-Tiny: Speed Meets Efficiency
YOLOv7-Tiny is designed for rapid inference on GPU-equipped edge devices. It uses E-ELAN to improve gradient flow, enabling diverse feature extraction without adding latency. With approximately 6.2 million parameters and 13.8 GFLOPs, the model delivers 286 FPS on high-end GPUs. On the Jetson Nano, its optimized configuration (d1w25) achieves a 65.7% mAP50-95 with sub-100 millisecond latencies.
A standout feature of YOLOv7-Tiny is its re-parameterization technique, which merges layers during inference to reduce computational load. This innovation makes it four times faster than YOLOv5m6 while maintaining comparable accuracy. It also outpaces YOLOv5s6 by 1.5×, with a 6.3% improvement in AP.
"YOLOv7 focus on optimise training process instead of model structure and meanwhile does not increase the inference time" – Juneta Tao
YOLOv5 with Advanced Modules
Building on the speed of YOLOv7-Tiny, YOLOv5 takes a different route by focusing on memory efficiency and compatibility across platforms. Enhanced versions of YOLOv5 incorporate IPA and MSCCR modules to improve accuracy without increasing resource demands. It also uses less CUDA memory during training compared to YOLOv7.
The YOLO-TLA variant, an upgraded YOLOv5s, offers a 4.6% boost in mAP@0.5 on the MS COCO dataset while maintaining a compact size of 9.49 million parameters. YOLOv5’s flexibility extends to deployment, working seamlessly across artificial intelligence and machine learning solutions for mobile, IoT, and cloud platforms. Frameworks like TFLite with XNNPACK for ARM processors or OpenVINO for Intel CPUs further enhance its usability. The latest YOLOv8n (Nano) improves edge efficiency with just 3.2 million parameters and 8.7 billion FLOPs.
YOLOv4-Tiny: Precision on CPU Devices
YOLOv4-Tiny is a strong choice for CPU-based edge devices, integrating Coordinate Attention (CA) modules to focus on relevant features and minimize background noise. This is essential for maintaining accuracy in resource-limited settings.
On a Raspberry Pi 4 CPU, a scaled YOLOv4 variant achieved 56.9% mAP50-95 with a latency of 0.5 seconds. Replacing standard layers with lightweight backbones like ShuffleNet or GhostNet further reduced the model size and GFLOPs while preserving real-time performance.
Here’s a quick comparison of these YOLO variants:
| Model Variant | Parameters | Target Hardware | Key Strength |
|---|---|---|---|
| YOLOv7-Tiny | 6.2M | Jetson Nano (GPU) | High-speed inference via re-parameterization |
| YOLOv5 Enhanced | 9.49M | Cross-platform (Mobile/IoT) | Memory efficiency and versatility |
| YOLOv4-Tiny | Varies | Raspberry Pi (CPU) | Strong CPU performance with attention mechanisms |
Alternative Lightweight Architectures for Edge Devices
When it comes to edge deployments, there are several alternatives to YOLO that bring their own strengths to the table. These architectures are designed to strike a balance between accuracy and efficiency, using different approaches like hybrid CNN–Transformer models or attention mechanisms. They complement YOLO by addressing specific needs unique to edge devices.
MobileViT: Combining CNNs and Transformers
MobileViT takes an innovative approach by blending the spatial efficiency of CNNs with the global context capabilities of Vision Transformers. This hybrid design overcomes the spatial limitations of traditional CNNs by using self-attention to capture long-range dependencies across an image.
The results are impressive: 78.4% top-1 accuracy on ImageNet-1k with only 6 million parameters. MobileViT also outperforms MobileNetv3 by 5.7% on MS-COCO and DeiT by 6.2% with a similar parameter count.
To cater to various edge device requirements, MobileViT offers two variants:
- MobileViT-S: Processes frames in 3.2ms with 5.6M parameters.
- MobileViT-XS: A more compact option, requiring 7.2ms per inference with 2.3M parameters.
Its compatibility with TensorFlow Lite, CoreML, and ONNX Runtime makes it a practical choice for real-time mobile applications. This makes MobileViT a strong option for mobile-first edge scenarios.
LRAU: Targeting Fine-Grained Detection
The Lightweight Recurrent Attention Unit (LRAU) is designed for tasks where distinguishing between small inter-class differences is critical. It uses a reinforcement learning framework to adaptively focus on discriminative regions, eliminating the need for expensive ground-truth part annotations. A greedy reward strategy helps speed up training, and its fully convolutional design ensures fast processing. This makes LRAU particularly effective for extracting pose-invariant details where traditional detectors may fall short.
SSD300 and Faster R-CNN for Edge Devices
While YOLO variants are often preferred for edge devices, traditional two-stage detectors like Faster R-CNN still excel in accuracy. However, their high computational demands make them less suitable for resource-constrained environments. For example, a detection network can require up to 1,000 times more FLOPs than a classification network.
Single-stage detectors like SSD address this by simplifying the detection process, skipping the region proposal stage for faster inference. Techniques like channel pruning, sparse training, and knowledge distillation help mitigate challenges such as loss of positional and feature information in deeper layers. Light-Head R-CNN is another edge-optimized variant that balances computational efficiency with detection capabilities.
| Architecture Type | Speed | Accuracy | Edge Suitability |
|---|---|---|---|
| Two-Stage (Faster R-CNN) | Slower; high FLOPs | Generally higher | Low without compression |
| One-Stage (SSD) | Faster; minimal memory | Variable; speed-optimized | High with optimization |
| Hybrid (MobileViT) | 3.2–7.2ms latency | +5.7% vs MobileNetv3 | High; mobile-first design |
Performance Comparison of Lightweight Models
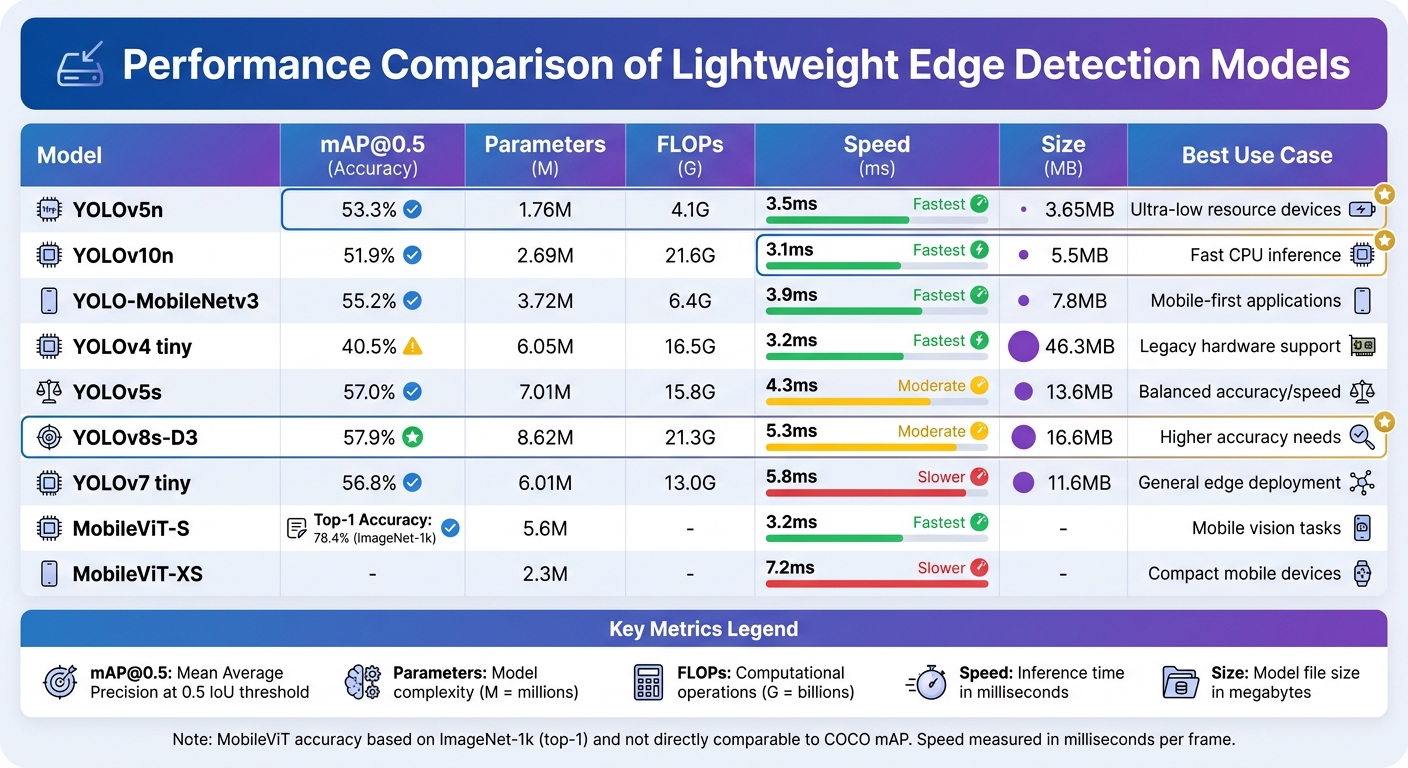
Performance Comparison of Lightweight Edge Object Detection Models
Picking the right lightweight model for edge deployment means balancing accuracy, speed, and resource efficiency based on your hardware and application requirements. Performance metrics like Mean Average Precision (mAP), inference latency, and memory bandwidth offer valuable insights into how well a model will perform in real-world scenarios.
Key Performance Insights
The mAP metric, often measured at various Intersection over Union (IoU) thresholds, is the go-to standard for accuracy. However, research suggests that inference latency often has a stronger correlation with detection accuracy than metrics like FLOPs or parameter counts. In other words, just because a model is smaller doesn’t mean it will run faster – new architectural modules can introduce overhead that affects speed.
Another critical factor is memory bandwidth, which often becomes the bottleneck on lower-end systems-on-chip (SoCs). For instance, on devices like the RV1106 or RK3568, multiple simultaneous tasks can lead to a 50–270% increase in inference latency. Additionally, performance scaling with theoretical TOPS (trillions of operations per second) is not linear; a 2× increase in TOPS typically translates to only a 1.3–2.0× speedup.
For real-time applications (30 FPS) on mid-tier hardware, Nano-scale models are usually the best fit. On an entry-level RV1106 (0.5 TOPS), these models achieve latency between 68–97 ms, while medium-scale models exceed 250 ms. High-end hardware like the RK3588 (2 TOPS per core) can bring latency down to 21–30 ms.
Comparison Table of Lightweight Models
| Model | mAP@0.5 (%) | Params (M) | FLOPs (G) | Speed (ms) | Size (MB) | Best Use Case |
|---|---|---|---|---|---|---|
| YOLOv5n | 53.3 | 1.76 | 4.1 | 3.5 | 3.65 | Ultra-low resource devices |
| YOLOv10n | 51.9 | 2.69 | 21.6 | 3.1 | 5.5 | Fast CPU inference |
| YOLO-MobileNetv3 | 55.2 | 3.72 | 6.4 | 3.9 | 7.8 | Mobile-first applications |
| YOLOv4 tiny | 40.5 | 6.05 | 16.5 | 3.2 | 46.3 | Legacy hardware support |
| YOLOv5s | 57.0 | 7.01 | 15.8 | 4.3 | 13.6 | Balanced accuracy/speed |
| YOLOv8s-D3 | 57.9 | 8.62 | 21.3 | 5.3 | 16.6 | Higher accuracy needs |
| YOLOv7 tiny | 56.8 | 6.01 | 13.0 | 5.8 | 11.6 | General edge deployment |
| MobileViT-S | 78.4* | 5.6 | – | 3.2 | – | Mobile vision tasks |
| MobileViT-XS | – | 2.3 | – | 7.2 | – | Compact mobile devices |
Note: MobileViT accuracy is based on ImageNet-1k (top-1) and is not directly comparable to COCO mAP. Speed is measured in milliseconds (ms) per frame.
Choosing the Right Model
To make an informed choice, focus on the Pareto frontier – models that strike the best balance between accuracy and speed. For extreme speed on CPU or NPU hardware, models like YOLO26n or YOLO26s are great picks. For more balanced performance, especially on legacy systems, YOLOv11s or YOLOv8s are better options. Be cautious with community models like YOLO12 and YOLO13, as they often suffer from training instability and high memory demands.
Best Practices for Deploying Lightweight Models on Edge Devices
Model Optimization Techniques
Optimizing your model is a critical step for deploying it effectively on edge devices. The goal is to reduce the model’s size and complexity without sacrificing its accuracy. One key approach is quantization, which converts 32-bit floating-point weights to 8-bit integers (INT8). This not only reduces the model size but also lowers power consumption, making it ideal for hardware with limited memory, such as microcontrollers with less than 1 MB of memory.
Another effective method is pruning, where unnecessary parameters and filters are removed to decrease computational load and storage needs. To take this further, combining pruning with knowledge distillation can be highly effective. In this process, a smaller "student" model is trained to replicate the performance of a larger, more precise "teacher" model. Simplifying the architecture by removing bottlenecks, like NMS and DFL, can also significantly improve efficiency. For instance, in January 2026, Ultralytics released YOLOv26, which achieved a 43% speed boost on CPUs compared to YOLOv11 by removing these components. The YOLOv26-n variant delivered approximately 39 ms latency on CPUs (ONNX) with a 40.9% mAP.
Edge Deployment Frameworks
Selecting the right deployment framework tailored to your hardware can greatly enhance performance. For NVIDIA Jetson devices, TensorRT is a top choice, offering advanced GPU utilisation through kernel auto-tuning and layer fusion. For ARM-based CPUs like the Raspberry Pi, frameworks such as NCNN and MNN often outperform TensorFlow Lite due to their optimised assembly kernels. A notable example occurred in April 2025, when YOLO11 was deployed on a Raspberry Pi 5 (8 GB) with NCNN, achieving over 25 FPS on 240×240 resolution frames. This reduced inference times by up to 62% compared to standard PyTorch weights.
OpenVINO is another versatile option, performing well on both Intel and ARM CPUs. Meanwhile, TensorFlow Lite provides broad compatibility for mobile devices and Edge TPU hardware, along with robust quantization tools. For Hailo-8 AI accelerators, HailoRT offers impressive performance for CNN-based tasks, although it struggles with transformer models due to its fixed-function hardware limitations. Once the model is optimised and deployed using the appropriate framework, real-world testing is essential to validate performance improvements.
Testing and Industry Applications
Testing your model on actual edge hardware is a must. Devices like the Raspberry Pi 5, equipped with a 2.4 GHz quad-core ARM Cortex-A76 processor, are commonly used for benchmarking edge AI performance. For UAVs or battery-powered devices, monitoring total system power – including CPU, memory, and accelerators – is crucial for ensuring battery efficiency.
In 2025, researchers introduced FRYOLO, an optimised YOLOv8 variant designed for real-time fruit defect detection in automated production lines. By shifting Distribution Focal Loss to the post-processing stage, the system achieved 33 FPS on IoT embedded devices, with 89.0% mAP and 92.5% precision.
Edge-based object detection is making waves in various industries, enabling real-time monitoring without relying on cloud connectivity. For example, a 2026 maritime surveillance study tested YOLO versions v6 through v11 on the NVIDIA Orin Nano platform. YOLOv8-based models stood out, maintaining power consumption under 2 W while delivering real-time throughput. The global Edge AI market is expected to grow to $206 billion by 2032, with an annual growth rate of 18.3%.
Companies like Digital Fractal Technologies Inc are leveraging these optimisation techniques to create scalable and purpose-built edge object detection systems. Their solutions are tailored to meet the demanding requirements of real-world applications across Canada and beyond.
Conclusion
Benefits of Lightweight Models for Edge Computing
Lightweight models are reshaping edge object detection by enabling local data processing, which eliminates network latency – a crucial factor for real-time applications like autonomous driving. They also reduce bandwidth usage, cutting down on data transmission costs and improving overall efficiency.
Local processing offers another major advantage: improved privacy and security. Sensitive data, such as healthcare records or consumer behaviour analytics, stays on the device, helping organisations comply with privacy regulations while safeguarding confidentiality. For battery-powered systems like vision-enabled UAVs and remote sensors, optimised models are indispensable. By maximising "frames per second per watt", they extend the operational lifespan of these devices. Techniques like quantization and pruning allow these models to deliver high-performance AI on hardware with limited memory – often under 1 MB – making them both resource-conscious and cost-efficient.
These improvements are setting the stage for purpose-built edge AI solutions, driving new opportunities in edge detection through hardware-aware designs tailored to specific needs.
The Future of Edge-Based Object Detection
Edge object detection is heading into a period of rapid growth and innovation. Building on advancements like YOLO variants and hybrid architectures, emerging areas such as TinyML and unsupervised edge learning are pushing boundaries. With IoT devices expected to surpass 150 billion by 2030, the demand for lightweight models is only going to grow.
Future developments will focus on hardware-aware architectures optimised for specific NPUs, GPUs, and TPUs. TinyML is already enabling deep learning on ultra-low-power microcontrollers with less than 1 MB of memory, opening up possibilities for what’s known as the "extreme edge". Hybrid designs combining CNNs and Transformers are improving the balance between local detail and global context, while unsupervised edge learning is paving the way for models that adapt autonomously to dynamic environments without relying on pre-labelled datasets.
The impact of these advancements is already visible across industries. Travel, transport, and logistics are leading the adoption of edge devices at 24.2%, followed by energy at 13.1% and retail at 10.1%. From predictive maintenance in industrial settings to patient monitoring in healthcare and smart grid optimisation in energy, lightweight models are enabling real-time, autonomous decision-making. Companies like Digital Fractal Technologies Inc are spearheading this transformation by creating scalable, edge detection systems tailored to meet the unique demands of Canadian industries and beyond.
FAQs
Which lightweight model should I choose for my edge device?
When it comes to edge object detection, the best model for your task depends on factors like accuracy, speed, and available resources. YOLO-Fast stands out for its impressive speed and accuracy, making it a great fit for datasets such as VisDrone. On the other hand, YOLO Nano, with a compact size of around 4 MB and a 69.1% mAP, is ideal for devices like the Jetson Nano.
If your needs are more specific, other YOLO versions like YOLOv8 or YOLO11 might be better suited, depending on your hardware and accuracy requirements. However, for a solid balance of performance and efficiency, YOLO-Fast and YOLO Nano are excellent options.
How can I boost FPS on edge hardware without losing much accuracy?
To boost FPS on edge hardware without sacrificing accuracy, you can apply strategies like quantization, pruning, and using lightweight architectures.
- Quantization shrinks model size by converting weights to lower precision, such as from 32-bit floating point to 8-bit integers. This speeds up computation and reduces memory usage.
- Pruning eliminates redundant channels or nodes in the model, streamlining its structure and improving efficiency.
- Lightweight models like YOLO-Fast or YOLO Nano are specifically designed for resource-limited devices. They deliver faster inference speeds while keeping accuracy at acceptable levels.
By combining these techniques, you can achieve higher FPS rates while still maintaining reliable detection performance.
What’s the best deployment runtime for Raspberry Pi vs Jetson?
The best runtime hinges on the hardware you’re working with. If you’re using a Raspberry Pi, ultra-lightweight models like YOLO11 or LEAF-YOLO-N are ideal since they’re optimized to perform efficiently with limited CPU power and memory. On the other hand, Jetson devices – such as the Nano or Orin NX – are better suited for larger models like YOLOv8 or RT-DETR. These devices take advantage of GPU acceleration and TensorRT to deliver real-time, high-accuracy detection. Ultimately, your choice should align with the platform’s computational capabilities and the complexity of the model you need.

