
Edge Computing vs Cloud: AI Workload Optimization
Edge computing and cloud computing are two key approaches to managing AI workloads and machine learning solutions, each suited to different needs. Here’s a quick summary:
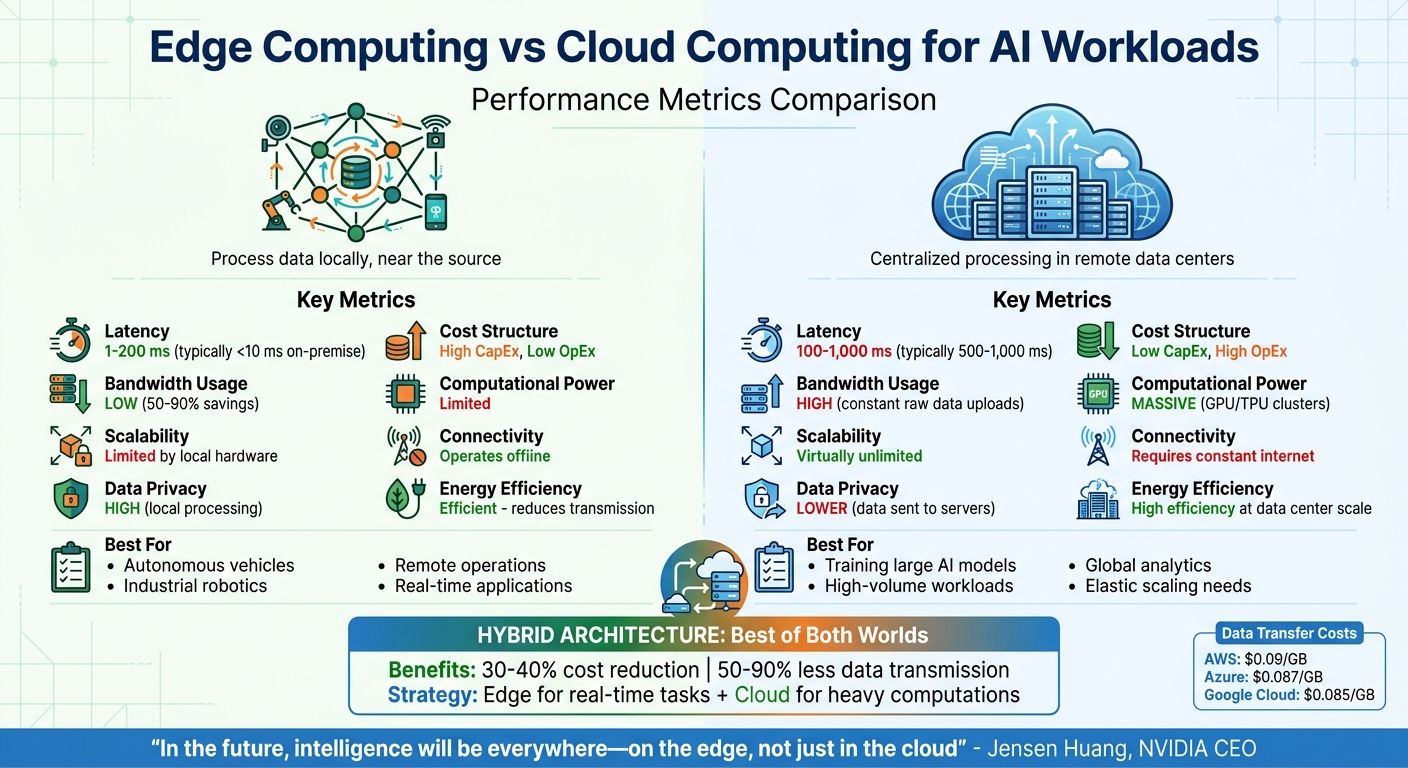
- Edge computing processes data locally, near its source, offering ultra-low latency (1–5 ms), reduced bandwidth usage (50–90% savings), and better offline functionality. It’s ideal for real-time applications like autonomous vehicles, industrial robotics, and remote operations.
- Cloud computing centralizes processing in remote data centres, providing scalable resources for tasks like training large AI models. It excels in handling high-volume workloads and tasks requiring extensive computational power, but typically involves higher latency (500–1,000 ms) and relies on stable internet connectivity.
Quick Comparison
| Metric | Edge Computing | Cloud Computing |
|---|---|---|
| Latency | 1–200 ms | 100–1,000 ms |
| Scalability | Limited by local hardware | Virtually unlimited |
| Data Privacy | High (local processing) | Lower (data sent to servers) |
| Cost Structure | High CapEx, low OpEx | Low CapEx, high OpEx |
| Bandwidth Usage | Low | High |
| Computational Power | Limited | Massive |
| Connectivity | Operates offline | Requires constant internet |
Hybrid architectures combine the strengths of both, leveraging edge for real-time tasks and the cloud for heavy computations. This approach can reduce costs by 30–40% and cut data transmission by 50–90%.
Choosing the right solution depends on your needs for latency, data sensitivity, scalability, and connectivity. This decision is a critical component of a broader digital transformation strategy for modern enterprises.
Edge Computing vs Cloud Computing for AI Workloads: Performance Metrics Comparison
Main Differences Between Edge and Cloud Computing for AI
Processing Location
The key difference between edge and cloud computing lies in where the AI processing happens. Cloud computing consolidates massive computing and storage resources in remote data centres, making it ideal for large-scale tasks like training complex AI models and conducting global analytics. On the other hand, edge computing shifts the processing closer to the data source – on devices like smartphones, sensors, or on-site servers.
This decentralisation with edge computing reduces the need for extensive data transfers, which can be expensive. For example, data transfer costs for major providers are approximately $0.09/GB for AWS, $0.087/GB for Azure, and $0.085/GB for Google Cloud. These differences in processing location significantly affect both latency and connectivity.
Latency and Connectivity
Edge computing is a game-changer for latency-sensitive applications. It can achieve latencies as low as 1–5 milliseconds on-premise and typically 100–200 milliseconds in distributed setups. In contrast, cloud solutions average around 500–1,000 milliseconds, making edge computing up to five times faster in scenarios where speed is critical.
Another advantage of edge computing is its ability to function independently of a continuous Internet connection. This makes it ideal for remote or disconnected environments like mines, oil rigs, or ships, where reliable connectivity isn’t guaranteed. For instance, NASA uses edge computing for Mars missions because of the 11-minute signal delay, enabling local decision-making without waiting for Earth-based instructions.
"The first sign that a cloud-first design is wrong often isn’t CPU saturation. It’s the network." – Fluence Network
While speed and connectivity are crucial, the choice between edge and cloud also has implications for data privacy and security.
Data Privacy and Security
Edge computing keeps data local, which can help businesses comply with regulations such as GDPR and HIPAA. By avoiding the transfer of sensitive data over networks, edge computing reduces certain security risks. However, this decentralised approach introduces its own challenges – each device becomes a potential vulnerability, requiring individual updates and physical protection.
In contrast, cloud computing typically offers unified security measures across global data centres. However, it operates on a shared responsibility model: the cloud provider secures the infrastructure, while users are responsible for protecting their data and AI models. This division of responsibilities can make security management more complex for cloud users.
sbb-itb-fd1fcab
Edge vs Cloud: AI Performance Comparison
Performance Metrics Overview
Optimizing AI workloads is all about matching performance metrics to your business priorities. Key metrics to consider include latency, scalability, data privacy, cost, energy efficiency, computational power, and connectivity. Here’s a quick breakdown:
- Latency: Measures how fast your system responds to requests – critical for real-time applications.
- Scalability: Determines how easily capacity can grow as demand increases.
- Data Privacy: Ensures compliance with regulations by controlling where data is processed and stored.
- Cost: Includes both upfront hardware investments and ongoing operational expenses.
- Energy Efficiency: Affects your operating costs and environmental impact.
- Computational Power: Defines the complexity of AI models your system can handle.
- Connectivity: Ensures your system remains functional even during network disruptions.
- Bandwidth Usage: Impacts data transfer costs and overall network performance.
Choosing the right architecture means balancing these factors carefully, as market trends show their increasing importance.
Comparison Table
| Metric | Edge Computing | Cloud Computing |
|---|---|---|
| Latency | <10–200 ms (usually <10 ms on-premise) | 100–1,000 ms |
| Scalability | Limited by local hardware; upgrades needed | Virtually unlimited; scales on demand |
| Data Privacy | High – data stays local | Lower – data sent to third-party servers |
| Cost Structure | High CapEx, low OpEx | Low CapEx, high OpEx |
| Bandwidth Usage | Low – filters data at source | High – requires constant raw data uploads |
| Computational Power | Limited – needs optimised models | Massive – supports GPU/TPU clusters |
| Connectivity | Operates offline | Requires constant internet |
| Energy Efficiency | Efficient – reduces transmission | High efficiency at data centre scale |
The table highlights edge computing’s strength in responsiveness and local processing, while the cloud delivers unmatched computational capacity and scalability. As NVIDIA CEO Jensen Huang puts it:
"In the future, intelligence will be everywhere – on the edge, not just in the cloud".
This trend points towards hybrid architectures that combine the best of both worlds. Edge computing is ideal for scenarios needing ultra-low latency, offline capability, or localised data handling. On the other hand, cloud computing is perfect for workloads requiring heavy computational power, elastic scaling, and lower initial investments. Together, these insights help shape strategies for deploying AI workloads across edge, cloud, or hybrid platforms.
Strengths of Edge and Cloud Computing in AI Optimization
Benefits of Edge Computing
Edge computing shines when speed and data protection are top priorities. By processing data locally, edge devices can deliver response times as quick as 1–5 milliseconds. This is critical for applications like autonomous vehicles, which require reaction times under 50 milliseconds to ensure safety. Such ultra-low latency also makes edge computing a perfect fit for industrial robotics, augmented reality, and real-time quality control.
Another major perk is its ability to reduce bandwidth usage. By filtering and analysing data directly at the source, edge computing can cut network traffic by 50% to 90%. This not only eases network congestion but also lowers data transfer costs. Additionally, edge devices can operate independently during network outages, making them ideal for remote environments like mines, oil rigs, or agricultural sites. It’s no surprise that 91% of companies see local data processing as a competitive edge.
These benefits make edge computing a go-to solution for AI tasks requiring immediate responses and localised data handling.
Benefits of Cloud Computing
Cloud computing provides the heavy-duty computational power needed for large-scale AI projects. Hyperscale providers offer instant access to vast GPU and TPU resources, allowing businesses to train deep neural networks and large language models without the need for costly hardware investments.
One standout feature of the cloud is its elastic scalability. For instance, Deutsche Bank moved 260 applications to the cloud to integrate generative AI into their operations, showcasing how the cloud can handle unpredictable AI workloads with ease. Similarly, Datacake manages 35 million daily messages from industrial machines worldwide with just three engineers, highlighting the efficiency and capacity of cloud platforms.
Centralised processing is another key strength. Cloud environments act as a hub, aggregating data from various sources for unified model training and analytics. This setup also streamlines collaboration across teams. For organisations already using cloud-based systems like ERPs or customer databases, running AI inference in the cloud avoids the hassle and costs of transferring massive datasets.
These features – scalability and centralised processing – make cloud computing indispensable for large-scale AI operations and pave the way for hybrid solutions that combine the best of both approaches.
Hybrid Edge-Cloud Architectures in AI
Why Hybrid Models Work
AI systems don’t operate as a one-size-fits-all solution. Instead, they combine the strengths of both edge and cloud computing to handle tasks based on factors like urgency, cost, and confidence. Here’s how it works: the edge takes care of immediate, lightweight decisions, while the cloud tackles more complex, resource-intensive analysis.
For instance, in an edge-first with cloud fallback setup, compact models run locally to make split-second decisions – perfect for robotics or safety-critical systems. When the decision is unclear, the system escalates the task to the cloud for deeper analysis. On the flip side, a cloud-first, edge-cache configuration processes data centrally but caches results at the edge, enabling faster reuse and reducing repetitive compute costs. Another popular approach preprocesses data at the edge to cut down on network transfers, with the main model running in the cloud.
These hybrid architectures deliver real benefits. They can lower inference costs by up to 40%. Plus, edge components ensure systems keep running during network outages, while the cloud simplifies tasks like updating models and managing central logs .
"The question is not whether cloud or edge is ‘better,’ because both are essential in a mature inference architecture."
– Jordan Mercer, Senior SEO Editor
This balance between performance and cost makes hybrid architectures a practical choice across different industries.
Industry Use Cases for Hybrid Architectures
Hybrid models are not just efficient – they’re versatile. By blending edge and cloud capabilities, industries can address challenges that demand both quick decisions and large-scale analysis.
Take healthcare, for example. Edge devices monitor patients in real time and anonymize sensitive data before sending it to the cloud. The cloud then aggregates this anonymized data for large-scale projects like genomic research or drug development. This setup keeps private health information secure while enabling broader medical advancements.
In manufacturing, edge sensors excel at detecting equipment failures and triggering emergency shutdowns in milliseconds. Meanwhile, cloud systems analyze long-term data trends to predict when maintenance is needed. A factory using 1,000 cameras for visual inspections can save massive bandwidth by processing data at the edge and sending only defect alerts instead of entire video feeds.
Canada’s energy sector also reaps the rewards of hybrid setups. Remote oil rigs and mining facilities use edge computing to monitor equipment in real time, even in areas with unreliable networks. At the same time, the cloud handles tasks like optimizing maintenance schedules and managing assets across multiple sites. Similarly, in the public sector, edge cameras detect traffic incidents locally in under 50 milliseconds, while cloud platforms analyze the broader data to improve city-wide traffic light coordination.
With 97% of CIOs already implementing or planning edge AI solutions, often starting with a digital transformation readiness assessment, it’s clear that hybrid architectures are becoming the go-to approach for organizations that need both speed and scalability. These examples highlight how this combination meets the demands of modern AI applications.
Edge Computing Vs. Cloud Computing – Key Differences to Know | Intellipaat
Conclusion: Choosing the Right Approach for AI Workload Optimization
The discussion above sheds light on the key factors to consider when optimizing AI workloads across edge and cloud platforms.
Key Takeaways
Edge and cloud computing each bring distinct advantages to AI workloads. Edge computing is perfect for applications needing ultra-fast responses, such as autonomous vehicles or industrial robotics, offering response times under 100 milliseconds. On the other hand, cloud computing shines when it comes to tasks like training massive models or performing batch analytics. This is reflected in the projected growth of the global cloud AI market, expected to jump from CA$78.36 billion in 2024 to a staggering CA$589.22 billion by 2032.
A hybrid approach combines the best of both worlds. By training models in the cloud using powerful GPU clusters and deploying optimised, lightweight versions at the edge, organisations can achieve real-time inference while lowering costs. This method can slash cloud inference expenses by 30–40% and reduce data transmission needs by 50–90%. For most production AI systems, a distributed architecture proves to be the most effective.
These strategies provide a roadmap for aligning technology choices with specific business goals.
Aligning Technology with Business Goals
Choosing the right computing strategy starts with understanding your organisation’s unique needs. To evaluate each AI workload, focus on four key factors:
- Latency: Applications requiring millisecond-level responses are better suited for edge computing.
- Data Sensitivity: Regulated environments often necessitate edge or on-premises solutions.
- Scale: High-volume workloads align well with cloud computing.
- Connectivity Reliability: When network stability is an issue, edge computing becomes the practical choice.
For instance, manufacturing operations might rely on edge computing for real-time defect detection, while using the cloud for predictive maintenance across an entire fleet. Similarly, in healthcare, edge computing can handle patient monitoring locally, while anonymised data is aggregated in the cloud for genomic research on a larger scale.
To ensure the strategy delivers results, consider launching a 90-day pilot programme in a single department. Tools like Kubernetes can help containerise AI workloads, making it easier to switch between cloud and edge environments. For customised guidance on developing an AI strategy, reach out to Digital Fractal Technologies Inc (https://digitalfractal.com).
FAQs
Which AI workloads belong on the edge vs in the cloud?
Edge computing shines when it comes to latency-sensitive and data-sensitive AI tasks. Think of real-time inference for autonomous vehicles, IoT devices, or industrial automation – situations where being close to the data source cuts down on delays and boosts privacy. On the other hand, the cloud is a better fit for resource-heavy tasks like model training, large-scale data crunching, or handling workloads that need to scale up or down quickly. It thrives on its ability to deliver massive computational power and flexibility. Many systems use a hybrid setup, with edge computing handling inference and the cloud taking care of training.
How do I decide if latency or data privacy matters more for my AI app?
The importance of latency or data privacy hinges on the specific requirements of your application. For tasks that demand real-time responses, like autonomous vehicles, minimizing latency is absolutely essential – this is where edge computing shines. On the other hand, if you’re dealing with sensitive information, such as health records, data privacy becomes the priority. In such cases, on-premise or edge solutions are often the better choice.
The key is to strike the right balance: focus on latency for time-sensitive operations, and emphasize privacy when managing confidential data, even if it means adding some complexity to your setup.
What’s the best way to start a hybrid edge-cloud AI pilot?
To kick off a hybrid edge-cloud AI pilot, follow a structured plan that focuses on latency, cost, and operational requirements. Begin by pinpointing which tasks are best handled at the edge – such as those requiring low latency – and which are better suited for the cloud, like large-scale data processing. Clearly define your Service Level Objectives (SLOs) to set expectations. Test the system’s performance and keep an eye on costs throughout the process. Use the insights and feedback you gather to gradually scale up, ensuring the solution aligns with your operational priorities.

