
AI Models for Small Object Detection in UAV Images
If you want the short answer: the best UAV small-object detectors usually win by keeping more image detail, mixing features across scales, and staying light enough for edge use.
I’d sum up the research like this: small targets in drone images often measure under 32 × 32 pixels, and standard downsampling makes them harder to find. Across papers, YOLO-based one-stage models show up most often because they balance accuracy and low-latency use better than two-stage systems. The strongest results usually come from three things: detail-preserving downsampling, high-resolution detection heads, and feature fusion with attention.
Here’s the plain-English version of what matters most:
- Tiny targets are the main problem. At common flight heights, objects may shrink to only a few pixels.
- Benchmarks change the story. VisDrone, UAVDT, and HIT-UAV test different scene types, so model rankings can shift.
- mAP50 alone is not enough. I’d also look at mAP50:95, recall, GFLOPs, parameter count, and FPS.
- YOLO variants lead most of the research. Recent models such as LRDS-YOLO, MFA-YOLO, MFDA-YOLO, MSD-YOLO11n, and SOO-YOLO focus on small-target detail instead of just making the network bigger.
- Training matters a lot. Methods like Mosaic, HSV shifts, random erasing, P2 heads, and tuned loss functions often make a clear difference.
- For deployment, size and latency matter as much as mAP. A model with lower compute and fewer parameters can be the better pick for UAV hardware.
A multi-scale small object detection algorithm SMA-YOLO for UAV remote sensing images
sbb-itb-fd1fcab
Quick Comparison
| Area | Main takeaway |
|---|---|
| Core challenge | Small objects lose detail fast after downsampling |
| Best model pattern | YOLO-based, one-stage, with multi-scale fusion and attention |
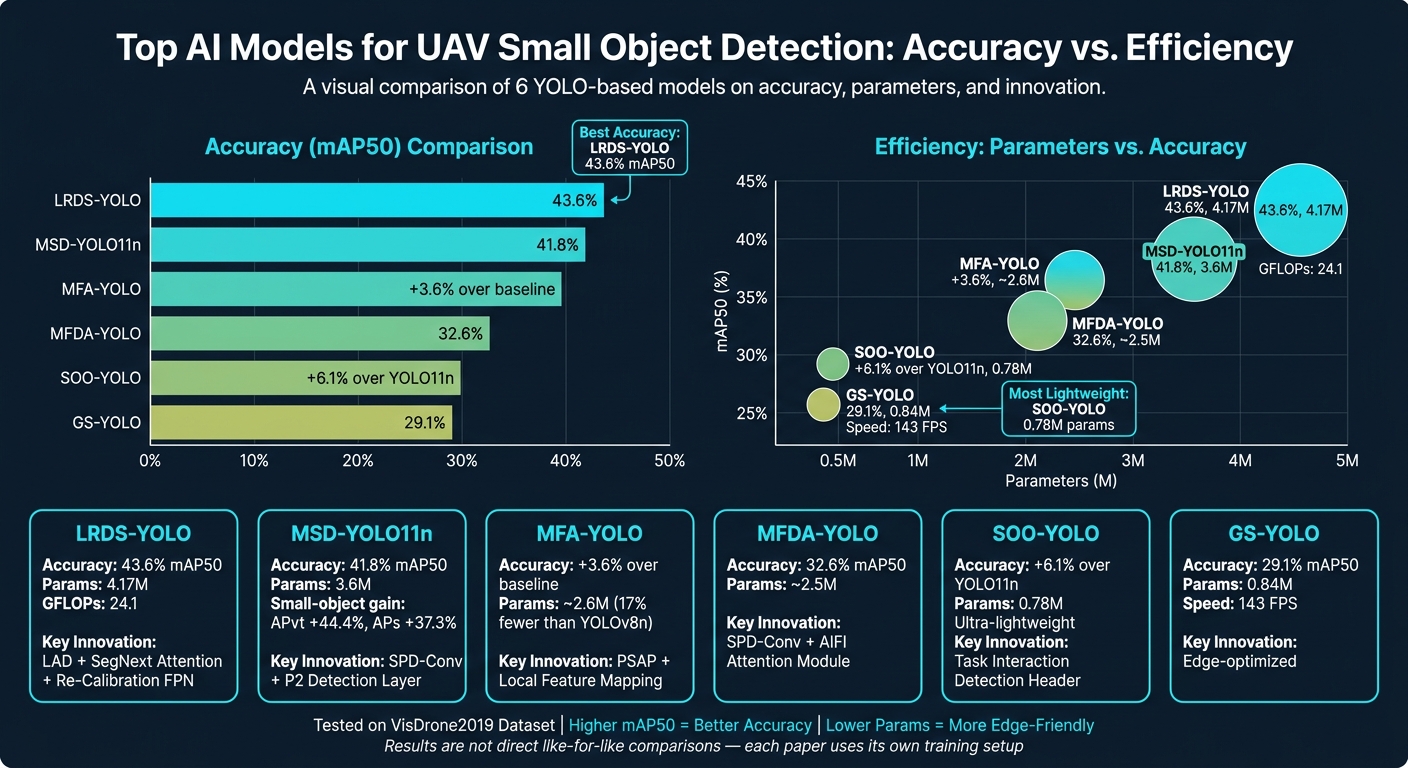
| Top reported VisDrone result in this set | LRDS-YOLO: 43.6% mAP50 |
| Lightweight edge-focused examples | SOO-YOLO: 0.78M params, GS-YOLO: 0.84M params |
| Strong small-object training trick | Add a P2 detection layer and keep shallow features |
| Best use case fit | Pick by accuracy + latency + model size, not one metric alone |
If you’re reading this for a Canada-based use case – like wildfire watch, traffic review, site safety, or infrastructure checks – the big lesson is simple: the best AI consulting and machine learning solutions are not just about the top score. It’s the one that can spot tiny targets fast enough, on the hardware you have, and with few misses.
Datasets, Benchmarks, and How Studies Measure Performance
VisDrone and UAVDT show up again and again in this research, and that matters. Their formats are different, so the same model can look strong on one benchmark and weaker on another.
Common UAV Datasets Used in the Literature
VisDrone covers urban surveillance across 10 object categories, with 8,629 static images split across training, validation, and test sets. UAVDT is centred on traffic monitoring – cars, trucks, and buses – across 100 videos with more than 80,000 labelled instances. Researchers often sample every 10th frame to turn it into a static image set of about 3,111 images. HIT-UAV adds infrared data, which makes it useful for low-contrast thermal scenes, across 2,898 images at 640 × 512 resolution.
| Dataset | Resolution | Images | Classes | Small-Object Scale | Application Domain | Video |
|---|---|---|---|---|---|---|
| VisDrone | High-resolution | 8,629 (static) | 10 | < 32 × 32 px | Urban surveillance, traffic | Yes |
| UAVDT | 1,024 × 540 | 100 videos; 80,000+ labelled instances | 3 | Depends on flight height | Traffic monitoring | Yes |
| HIT-UAV | 640 × 512 | 2,898 | Various | Infrared targets | Thermal/Rescue | Not specified |
The gap between these benchmarks is big enough to shuffle model rankings. A detector that does well on traffic footage might not hold up the same way in dense urban scenes or thermal imagery.
Metrics That Matter Beyond mAP50
Dataset choice shapes the result, but metrics shape the story. mAP50 is still the main number most papers lead with, but on its own, it can gloss over poor box placement. mAP50:95 averages precision across IoU thresholds from 0.5 to 0.95, so it gives a stricter read on localisation quality. If the job depends on placing boxes with care, mAP50:95 tells you more than mAP50.
Recall also matters a lot, especially when the cost of missing a target is high. A model with high recall misses fewer real objects, even if it sometimes marks something that is not there. In search-and-rescue or security work, a missed detection is often worse than a false positive.
On the compute side, GFLOPs and parameter count show how heavy a model is, while FPS tells you whether it can handle a live video stream. That trade-off between accuracy and edge-device compute is one of the main limits on deployment. This challenge highlights the need for expert AI insights when architecting high-performance systems. LRDS-YOLO reached 43.6% mAP50 on VisDrone2019 with 4.17 million parameters and 24.1 GFLOPs, which is a good example of why speed and model size matter just as much as top-line accuracy.
AI Model Architectures That Perform Best on Small UAV Targets
Top AI Models for UAV Small Object Detection: Accuracy vs. Efficiency
Once the benchmark results are clear, the next step is figuring out why some models do better than others. Across the research, One trend keeps showing up: YOLO-based one-stage detectors lead most small-UAV detection work, often integrated into AI enhanced mobile and web apps for real-time field analysis.
Why YOLO-Based and One-Stage Detectors Lead UAV Research
Two-stage detectors tend to add delay, which makes them a poorer fit for UAV use. One-stage YOLO models are usually a better match when speed matters. At the same time, newer YOLO versions have narrowed much of the accuracy gap that once pushed people toward two-stage designs. YOLOv8 and newer releases also shifted to anchor-free detection with better sample assignment, which cuts sensitivity to hyperparameter tuning and helps in cluttered aerial scenes.
Feature Fusion, Attention, and High-Resolution Heads for Small Objects
A plain YOLO backbone usually isn’t enough for tiny UAV targets. The best models tend to add a few specific changes that help keep detail intact and improve multi-scale context.
One of the biggest upgrades is detail-preserving downsampling. Standard strided convolutions can throw away small visual cues too early. Methods like Light Adaptive-weight Downsampling (LAD) and Space-to-Depth convolutions (SPD-Conv) help keep fine-grained information before features reach the detection head. In cluttered scenes, that matters a lot because clearer object boundaries can mean the difference between a hit and a miss.
High-resolution detection heads help too. By making predictions from less-downsampled feature maps, they keep more of the tiny-object signal alive.
Multi-scale fusion is just as important. Standard FPN and PANet are still common starting points, but stronger models push this further. LRDS-YOLO uses a Re-Calibration FPN, while MFA-YOLO uses a Progressive Shared Atrous Pyramid (PSAP). Both are built to gather context across scales without washing out the small-object signal. Attention modules also play a big part. SegNext and AIFI (Attention-based Intra-scale Feature Interaction) help the network focus on the parts that matter and tone down background noise in aerial imagery.
Model Comparison by Accuracy and Efficiency
The models below show the patterns behind the best results. These numbers are directional, not perfect like-for-like comparisons, because each paper uses its own training setup.
| Model | Base Architecture | Key Architectural Feature | Parameters | GFLOPs | Reported Result (VisDrone) |
|---|---|---|---|---|---|
| LRDS-YOLO | YOLOv11-based | LAD + SegNext attention + Re-Calibration FPN | 4.17M | 24.1 | 43.6% mAP50 |
| MFA-YOLO | YOLOv8 | PSAP + Local Feature Mapping (LFM) | ~2.6M (17% fewer than YOLOv8n) | – | +3.6% AP50 over baseline |
| MFDA-YOLO | YOLOv8-based | SPD-Conv + AIFI module | ~2.5M (17.2% fewer than YOLOv8n) | – | 32.6% mAP50 |
| SOO-YOLO | YOLO11-based | Task interaction detection header | 0.78M | – | +6.1% AP50 over YOLO11n |
| YOLOv8n | Baseline | Standard FPN/PANet, anchor-free design | 3.2M | 8.7 | ~31–32% mAP50 |
The biggest gains don’t come from making the model bigger. They come from keeping detail, improving feature fusion, and using attention in the right places. LRDS-YOLO, for example, reaches 43.6% mAP50 on VisDrone2019 – 11.4% higher than its baseline – while staying fairly compact at 4.17M parameters and 24.1 GFLOPs. Those same design choices also influence the training methods discussed next.
Training Methods and Key Findings from Published Studies
Training choices often decide whether small-object gains show up in practice. Model design matters, of course. But data prep, augmentation, and loss design often make just as much difference. In many of the published studies, the biggest gains come from how the model is trained, not just which backbone or head it uses.
Data Preparation Methods That Improve Tiny Target Visibility
For tiny UAV targets, keeping shallow, high-resolution features intact is a big deal. If those early details get lost, the model is already in trouble. SPD convolutions and a P2 detection layer help hold onto fine-grained detail for very small objects. That setup helped MSD-YOLO11n reach 41.8% mAP0.5 on VisDrone2019, with strong gains on tiny objects.
Once that detail is preserved, augmentation does the heavy lifting for messy scenes. Studies point to a mix of:
- Mosaic
- Horizontal flip
- HSV adjustment
- Random erasing
- Attention-based fusion modules such as SOLCA, DyHead, and DySample
These methods help models deal with clutter, partial occlusion, and busy backgrounds.
After data preparation, the next big lever is loss design.
Loss Functions, Optimisation Settings, and Performance Trends
Across the studies, the training recipe is fairly consistent: SGD with momentum 0.937, weight decay 0.0005, and an initial learning rate of 0.01 over 300 epochs. That kind of setup shows up again and again for a reason – it gives a stable baseline for comparison.
Focaler-PIoUv2 improves hard-sample learning and convergence without added compute. That matters when small targets are easy to miss and hard examples can shape the final result.
One trend shows up pretty clearly in the literature: multi-scale selective fusion and scale sequence feature fusion tend to deliver more dependable gains than simply adding extra detection layers. More heads might sound like an easy win, but they can increase compute cost without giving much back in small-object accuracy.
Real-Time vs. Offline Analysis: What the Evidence Shows
The table below shows how these choices play out in accuracy and speed. FPS numbers depend on hardware, so treat them as directional rather than fixed.
| Model | Dataset | Input Size | mAP50 | Small-Object Result | Efficiency Signal |
|---|---|---|---|---|---|
| LRDS-YOLO | VisDrone2019 | – | 43.6% | – | 4.17M parameters; 24.1 GFLOPs |
| MSD-YOLO11n | VisDrone2019 | 640 × 640 | 41.8% | APvt +44.4%; APs +37.3% | 3.6M parameters |
| MFRA-YOLO | VisDrone2019 | 640 × 640 | 31.5% | – | 143 FPS |
| GS-YOLO | VisDrone | 640 × 640 | 29.1% | +0.9% over YOLOv8n | 0.84M parameters |
LRDS-YOLO posts the top accuracy in this group, while GS-YOLO and MFRA-YOLO lean harder into speed. Put simply, the best option depends on the job. If you’re working with live video, speed can matter more than squeezing out a few extra points of mAP. If you’re doing offline review, the balance can shift the other way.
Deployment Considerations and Conclusion
From Research Models to Production UAV Software
Strong benchmark results are one thing. Running a detector on an actual UAV is another.
Once you move into production, the trade-offs get real: latency, memory use, battery drain, and accuracy all start pulling in different directions. The core question is simple: can these detectors still perform within UAV power and response-time limits?
That’s why onboard constraints matter so much. UAVs need models that fit tight power, memory, and latency budgets. Lightweight architectures such as SOO-YOLO with 0.78M parameters and GS-YOLO with 0.84M parameters were built with that limit in mind, which makes them a good fit for edge deployment.
In production, teams usually run inference onboard or at the near edge to keep latency low and performance steady in high-altitude, low-contrast scenes. Reparameterization methods such as DEConv help here too. They keep training flexible, then fuse into a standard convolution at inference time, with no extra compute cost in production.
That helps explain why compact models and inference-efficient training methods often matter more than top-line accuracy by itself. Digital Fractal Technologies Inc can help connect UAV detectors to dashboards, incident alerts, and reporting workflows for Canadian public-sector, energy, and construction teams.
Key Takeaways and Future Research Directions
A few patterns show up again and again.
- Results shift a lot by dataset, especially when comparing infrared scenes with urban RGB footage.
- Multi-scale fusion, attention, and adaptive downsampling keep coming up because they help retain tiny-object detail after repeated downsampling.
- For deployment, model selection should balance accuracy, latency, and model size together, not treat any one of them in isolation.
Looking ahead, the most promising directions include thermal-visible fusion for night and low-visibility operations, domain adaptation across seasons, continual learning to adjust to data drift, and tracking-by-detection to maintain target continuity across frames. That’s the next step for UAV detection systems.
FAQs
Which metric matters most for small-object UAV detection?
The key metric is Average Precision (AP). In object detection, people often look at AP across different IoU thresholds, especially AP50 and AP50:0.95.
These scores show how well a model finds small targets in UAV images. Put simply, they help you see whether the model is not just spotting an object, but placing the bounding box in the right spot too.
How do I choose between accuracy and real-time speed?
Choose based on what your application needs most. GS-YOLO offers a strong middle ground, with 33.6% mAP50 on VisDrone and 70.42 FPS. LRDS-YOLO also aims to improve detection accuracy while keeping real-time performance on resource-constrained platforms.
If low latency matters most, go with speed. If detection precision matters more and a bit of latency is fine, pick a model that leans more toward accuracy.
Which UAV dataset is best for my use case?
The best UAV dataset depends on what you’re trying to do.
VisDrone2019 is one of the most used options for small object detection in UAV images. It includes more than 2.6 million annotations across a range of categories.
DOTA is another strong choice. It also includes detailed object annotations and works well for small object detection tasks.

