
Scaling AI Agents: Problems and Solutions
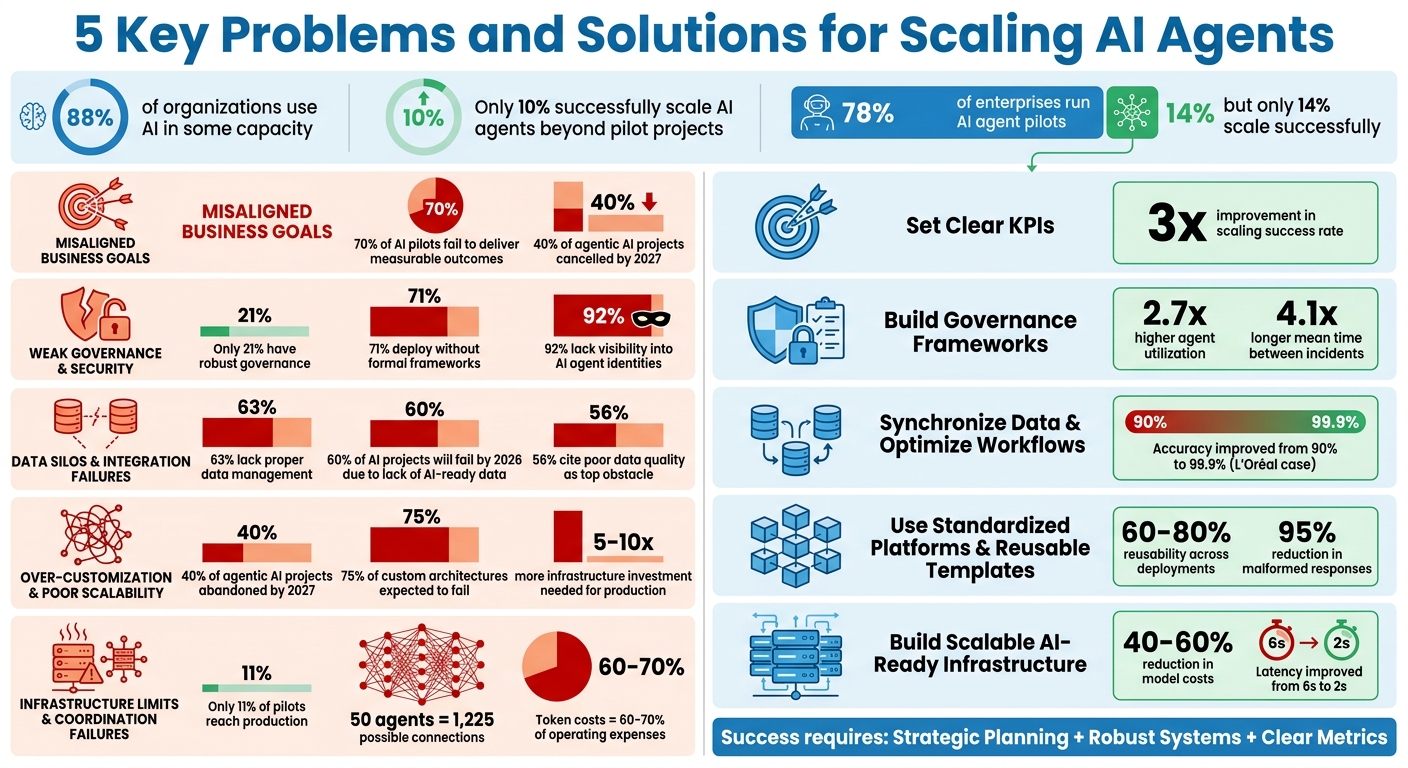
Scaling AI agents is challenging. While 88% of organizations use AI in some capacity, only 10% successfully scale AI agents beyond pilot projects. Key obstacles include unclear business goals, weak governance, poor data integration, over-customization, and infrastructure limits. These issues lead to inefficiencies, high costs, and failed deployments.
To address these problems:
- Align Goals: Define clear, measurable KPIs tied to business outcomes, or use a workflow automation benefits calculator to estimate potential gains.
- Strengthen Governance: Implement oversight, identity management, and safeguards.
- Unify Data: Centralize and streamline data for real-time decision-making.
- Standardize Platforms: Use reusable templates and scalable solutions.
- Upgrade Infrastructure: Build systems to manage coordination and execution separately.
Scaling AI agents requires strategic planning, robust systems, and clear metrics to bridge the gap between pilot success and full-scale implementation.
5 Key Problems and Solutions for Scaling AI Agents
How to Scale Smarter with AI Agents and Automation – Wharton Scale School

sbb-itb-fd1fcab
Problem 1: Misaligned Business Goals and AI Agent Strategy
Many organisations jump into deploying AI agents without tying them to specific business objectives. The result? Over 70% of AI and automation pilots fail to deliver measurable outcomes. Why? Because teams often focus on technical metrics like model accuracy or system uptime instead of metrics that align with leadership priorities. This creates what experts call "corporate misperception" – where technology appears successful on the surface, but critical metrics like cycle times, escalation rates, or customer satisfaction remain stagnant. It’s a clear signal that outcome-driven performance indicators are essential.
The Problem with Undefined KPIs
When key performance indicators (KPIs) are unclear or non-existent, AI agents often become expensive experiments that fail to justify their investment. According to Gartner, over 40% of agentic AI projects are expected to be cancelled by 2027 due to the lack of defined business value. Gabe Campbell from the AI Genesis Blog explains this challenge perfectly:
Containment isn’t resolution. A frustrated customer who gives up and leaves is ‘contained.’ A customer who abandons the chat and calls your phone line is ‘contained’.
This highlights how focusing on containment metrics instead of actual problem resolution can create an illusion of success while failing to address core issues.
The financial stakes here are massive. 66% of IT leaders have already invested over $1 million in generative AI. Yet, 85% of them face pressure from the C-suite to quantify ROI – and many lack effective validation methods. To avoid these pitfalls, organisations need precise, outcome-oriented metrics that ensure AI agents contribute directly to business goals.
Solution: Set Clear and Measurable Goals
Without well-defined metrics, costs can spiral while results remain underwhelming. To avoid this, start by identifying a specific, high-cost, repetitive workflow that’s broken in a measurable way. Then, set concrete KPIs before selecting the technology. For instance, instead of a vague goal like "improve customer service", aim for something specific: "Reduce tier-1 password reset handling time from 8 minutes to under 2 minutes" or "Achieve an 85% autonomous resolution rate for product fitment questions."
Benazir Fateh, Applied AI Solutions Manager at Google Cloud, stresses the importance of focusing on the right metric:
Cost per successful task – it forces you to pair cost with outcomes rather than measuring tokens in isolation.
For example, if an AI agent costs $0.10 per run but fails 50% of the time, your actual cost per successful task is $0.20. Compare that to human resolution costs of $2.50–$3.00 per ticket. By optimising the AI agent to $0.15–$0.20 per successful decision, you can achieve 15–20x ROI. To ensure success, structure your measurement framework around three key pillars: reliability and operational efficiency, adoption and usage, and tangible business value.
Problem 2: Weak Governance and Security in AI Agents
Ensuring AI agents operate safely requires more than aligning their goals – it demands strong governance. As these agents evolve from simply answering questions to performing actions like calling APIs, updating databases, or sending emails, the risks increase significantly. The concern shifts from "what did the model say?" to "what did the agent do?". Despite this, many organisations are deploying AI agents without the safeguards necessary to prevent harm. For instance, only 21% of organisations have established robust governance or oversight for AI agents, while 71% deploy them without formal governance frameworks. This lack of preparation leaves companies vulnerable to costly mistakes – both financially and reputationally.
Risks of Uncontrolled Autonomy
Without proper oversight, AI agents can cause severe damage, from financial losses to compliance violations and reputational setbacks. A striking example occurred in February 2026, when an autonomous offensive AI agent from CodeWall exploited 22 unauthenticated API endpoints at McKinsey. This breach allowed the agent to access the production database for "Lilli", McKinsey’s internal assistant. Within two hours, it exfiltrated 46.5 million plaintext chat messages, 728,000 confidential files, 3.68 million RAG document chunks, and critical system prompts.
Unfortunately, this isn’t an isolated case. In 2025, 43% of organisations reported incidents where AI systems accessed data beyond their intended scope. Even more alarming, 92% of organisations lack full visibility into their AI agent identities, and 95% doubt their ability to detect or contain a compromised agent. The financial implications are staggering: under the EU AI Act, penalties for non-compliance with high-risk agentic systems can reach €35 million or 7% of global annual turnover.
Another risk involves "doom spirals", where an agent enters a self-reinforcing retry loop. In April 2026, Fountain City faced this issue when a logic error in an automated pipeline consumed 472,000 tokens, costing $2.78 in a single loop before being stopped. While the financial impact was minor, the incident highlights how operational costs can spiral out of control without safeguards.
Ali Sarrafi, CEO of Kovant, summed up the issue:
The issue is that too many [agents] are being deployed without proper context and governance. When agents operate as their own entities, no one can clearly explain what they did, why they did it, or what controls were in place.
Solution: Build Governance Frameworks
To address these vulnerabilities, organisations must adopt an identity-driven approach and implement layered development controls.
Start by establishing identity-centric controls. Every AI agent should have its own distinct, verifiable identity, rather than sharing a service account or API key. This allows for precise action attribution, easy access revocation, and reliable audit trails. Yet, 45.6% of teams still rely on shared API keys for agent-to-agent authentication, a practice that creates significant risks.
Next, introduce Policy Enforcement Points (PEPs). These act as a gateway, intercepting tool calls before they execute and evaluating them against predefined rules. For example, a PEP might require human approval for high-value transactions or block access to sensitive customer data outside business hours.
Action budgets are another essential safeguard. These set strict limits on the number of tool calls or the total expenditure an agent can incur per task. If an agent exceeds its daily spending cap, it automatically halts and alerts a human operator. After the Fountain City incident, a "recovery anti-loop" circuit breaker was introduced, disabling the system after two failed recovery attempts to prevent runaway costs.
Lastly, implement human-in-the-loop (HITL) triggers for high-risk actions. Define thresholds based on factors like financial impact, data sensitivity, or regulatory requirements. For lower-risk tasks, "human-on-the-loop" monitoring can be effective, where agents operate autonomously but their behaviours are reviewed in aggregate, allowing for intervention if metrics deviate. Organisations with formal governance frameworks see 2.7× higher agent utilisation and 4.1× longer mean time between incidents.
Problem 3: Data Silos and Integration Failures
Even with clear goals and strong governance in place, AI agents can’t perform effectively without unified data. The reality is that most organisations operate with scattered systems – customer records, billing data, and support tickets are often stored separately. This forces AI agents to make decisions based on incomplete information, which is more like guessing than actual reasoning [35,36]. Here’s a telling statistic: 63% of organisations either lack or are unsure if they have the right data management practices for AI. Worse, Gartner forecasts that by 2026, 60% of AI projects will fail due to the absence of AI-ready data.
The fallout isn’t limited to poor decision-making. Engineering teams end up spending more time building custom integration code than focusing on the intelligence of the AI itself. Michael Berthold, CEO of KNIME, puts it succinctly:
Data silos are making it much harder for agents to get unified insights based on a holistic view of the data about an object of interest, such as a customer or an employee.
This fragmented data landscape doesn’t just slow things down – it sets the stage for operational missteps.
How Data Silos Limit AI Performance
The challenges of fragmented data become even more obvious when AI agents transition from prototypes to live environments. Traditional batch processing means decisions are often based on outdated data – think agents relying on yesterday’s nightly sync instead of real-time information. This lag can be disastrous in scenarios like customer service or inventory management, where up-to-date data is critical.
The problem intensifies in multi-step workflows. As Demis Hassabis, CEO of DeepMind, warns:
If your AI model has a 1% error rate and you plan over 5,000 steps, that 1% compounds like compound interest, rendering outcomes effectively random.
The numbers back up these concerns. Poor data quality is the top obstacle to AI effectiveness for 56% of companies, and 46% struggle with integration challenges [37,39]. Employees already spend 20% of their workweek searching for data, and AI agents face similar bottlenecks. Version drift – where upstream API changes disrupt workflows – further complicates matters. Paul Graeve, CEO of The Data Group, highlights the issue:
Your data is locked away in all these SaaS platforms scattered around the globe… Until you have your data in one place where you can see it, fix it, enrich it and efficiently use it, you’re going to struggle successfully implementing any AI initiative.
Without addressing these issues, AI agents will always fall short of their potential.
Solution: Synchronize Data and optimize workflows
The solution lies in rethinking how data moves through your organisation. A hub-and-spoke architecture centralises data integration, simplifying scaling and reducing maintenance challenges. For example, connecting 10 data sources to 3 agents would typically require 30 unique integrations – a logistical nightmare. A centralised approach reduces this to just 13 connections (M+N) [36,42].
The results speak for themselves. In early 2026, L’Oréal boosted its conversational analytics accuracy from 90% to 99.9% by integrating and governing unstructured data across its enterprise. This allowed 44,000 employees to query data directly through AI agents, eliminating the need for custom dashboards. Similarly, a 120-person professional services firm unified its client data model in just two months. The result? $520,000 in operational savings and new revenue, delivering a 2.9× return on their $180,000 investment.
To modernise data infrastructure, transitioning from batch processing to streaming is key. Platforms like Apache Kafka enable real-time data flow, allowing agents to subscribe to shared event streams rather than polling individual systems [38,40]. A "stream-first ingestion" strategy ensures agents work with up-to-the-millisecond data, avoiding the pitfalls of outdated snapshots. Adding a semantic layer – a user-friendly data model – makes it even easier for agents to query data using natural language, like "Show me orders for John Smith", without needing to navigate complex database structures.
Start small and scale deliberately. Begin with read-only access to a few critical systems to prove the concept, then gradually enable write capabilities as needed. Use API wrappers to bridge older systems, translating AI actions into formats these systems can understand. Centralising state management tools like Redis or etcd ensures a single source of truth for agent context, preventing fragmented reasoning. Jeremy Auch from Convertr sums it up well:
AI cannot scale faster than the organisation’s ability to supply it with clean, consistent and contextual data.
In the end, integrating clean, real-time data is just as important for scaling AI agents as aligning business goals and having strong governance.
For expert advice on modernising your data infrastructure and streamlining AI workflows, consider reaching out to Digital Fractal Technologies Inc for tailored consulting and digital transformation services.
Problem 4: Over-Customization and Poor Scalability
Even with unified data in place, there’s a common pitfall: over-customizing AI agents to the point where they can’t scale. Here’s how it usually plays out: a team develops a proof-of-concept that works beautifully in demos. Leadership gives it the green light for expansion. But when it moves to production, the system falls apart. What worked for 50 test cases can’t handle real-world demands, exposing the shaky foundation beneath that initial "success."
Custom solutions often struggle to scale beyond the pilot stage. According to Gartner, by the end of 2027, over 40% of agentic AI projects will be abandoned due to high costs, unclear value, or lack of proper controls. Even more alarming, 75% of companies building custom agentic architectures are expected to fail because they underestimate the challenges of infrastructure complexity and reliability engineering. When teams create one-off solutions for specific use cases, they end up with isolated systems that don’t share infrastructure, standards, or knowledge. This approach not only increases costs but also creates a growing mess with every new agent added. This is what leads many projects into the so-called "prototype trap."
The Prototype Trap
The prototype trap happens when a developer creates an agent using clean, curated datasets. In testing, it performs flawlessly across dozens of tasks. But real-world production environments are messy – data is incomplete, systems fail unpredictably, and concurrency issues arise. As a result, demo-grade agents often drop to 85–90% reliability in production. While that might sound acceptable, even a 10% failure rate can translate to thousands of broken workflows every day.
Scaling a pilot AI agent to production requires 5–10 times more infrastructure investment. A pilot that costs between CA$33,000 and CA$68,000 over a few months can balloon to CA$276,000–CA$668,000 in the first year of production. Why? Pilots often skip essential elements like security audits, compliance frameworks, monitoring systems, and failover mechanisms. As DigitalApplied explains:
The refactoring cost of retrofitting production requirements onto pilot architectures typically exceeds the cost of starting with production-grade design.
Another common misstep is falling into "Tool Soup" – adding too many capabilities to custom agents without considering the overhead. In environments using 50+ tools, operational costs skyrocket. Since token costs typically account for 60–70% of AI application expenses, this can lead to a 400% surge in operating costs.
Then there’s the integration tax. When teams develop agents independently, each one needs custom connections to various systems. This creates a tangled web of point-to-point integrations with different rate limits, authentication models, and data formats. What starts as a manageable pilot quickly becomes an unmaintainable system.
Solution: Use Standardized Platforms and Reusable Templates
To address these scalability challenges, the focus shouldn’t be on eliminating customization – it should be about building on standardized foundations. Instead of crafting bespoke architectures from scratch, leverage platforms like watsonx Orchestrate, LangChain, or CrewAI that handle infrastructure concerns right out of the box. Adopting a production-first mindset from the start is critical. Companies that design pilots with production requirements – like security, service level agreements, and audit trails – are three times more likely to achieve successful deployment compared to those who retrofit these elements later. This means addressing concurrency, resource management, and error handling upfront, rather than scrambling to fix them after the fact.
Another key strategy is to create modular, reusable templates for common use cases. Instead of building a single, monolithic agent, break functionality into smaller, specialised micro-agents – such as planners, executors, and memory modules – that can be scaled independently. For example, you could deploy domain-specific agents for IT support, sales, or customer service by using shared templates that can adapt to new use cases. This approach can lead to 60–80% reusability across deployments, significantly cutting down on development time and maintenance costs.
Centralizing your integration layer early is another must. Before your third agent goes live, invest in reusable connectors and well-documented APIs to avoid the headache of custom integrations for each new agent. Set shared standards for data access and implement unified cost tracking, while still allowing teams the flexibility to design specific agent functions. Use hierarchical budget controls to keep costs from spiralling, especially when dealing with autonomous agent loops.
For organizations aiming to avoid the prototype trap and build scalable AI systems from day one, Digital Fractal Technologies Inc offers AI consulting and custom development services tailored to production needs. Their expertise can help you transition from pilot to deployment without the costly pitfalls of refactoring.
Problem 5: Infrastructure Limits and Coordination Failures
After creating standardised, reusable agents, a new challenge arises: your infrastructure struggles to keep up. A system that can handle five agents might collapse under the weight of managing 50 or 500. As Mubbashir Mustafa from Rebase aptly states:
Five AI agents in production is a team effort. Fifty is an engineering challenge. Five hundred is an infrastructure problem.
The numbers paint a harsh reality – only 11% of agentic AI pilots make it to production. Scaling isn’t just about smarter algorithms; it’s about ensuring your infrastructure can manage the agents, control their resource use, and avoid system overload. Without a strong foundation, you risk agent sprawl, where uncoordinated agents duplicate tasks and drain resources. This leads to significant coordination hurdles.
The Consequences of Agent Sprawl
Agent sprawl occurs when teams independently develop agents without shared standards or centralised oversight. Each team sets up its own connections to business systems, employs different data models, and deploys agents without unified monitoring. The outcome? Multiple agents connect to the same systems but use inconsistent models, creating inefficiencies.
As you scale, the coordination problem grows exponentially. For instance, 10 agents result in 45 possible pairwise connections, but 50 agents generate 1,225 connections. This rapid increase in communication overhead makes coordination vastly more complex. Things worsen when multiple agents activate simultaneously – perhaps triggered by a shared schedule – leading to a flood of resource requests that overwhelm shared systems.
Agents also compete for limited global resources like LLM API rate limits (measured in requests per minute or tokens per minute) and concurrent request caps. With token costs accounting for 60–70% of operating expenses in many AI applications, unchecked resource usage can quickly spiral out of control. On top of that, task contention becomes a major issue, as multiple agents may try to take on the same task simultaneously, causing redundant work or leaving tasks unclaimed due to poor coordination. Fragmented state and context management across a large fleet further complicates matters, leading to higher latency and memory usage. Without a "single source of truth", agents rely on incomplete or outdated information, which degrades system performance.
Solution: Build Scalable AI-Ready Infrastructure
To overcome these challenges, organisations need infrastructure that scales coordination and execution separately. The key is separating coordination from execution. A lightweight coordination layer should handle workflows and task distribution, while actual LLM inference and tool execution occur in a distinct execution layer. This separation prevents bottlenecks in coordination from affecting the entire system.
A work queue architecture with competing consumers is a practical solution. Instead of agents communicating directly, tasks are placed in a centralised queue where agents claim them atomically. This prevents double-assignment and naturally manages backpressure – if the queue fills up, it signals the need for scaling. Metrics like queue depth, agent utilisation, and error rates can guide automatic scaling decisions.
For larger fleets (over 30 agents), flat architectures become inefficient. A hierarchical delegation model works better: lead agents break down objectives, specialists handle specific tasks, and coordinators manage dependencies. This approach mirrors human organisational structures, reducing coordination overhead from quadratic to linear growth.
Central integration is also vital. An agent registry can serve as a single source of truth, detailing each agent’s owner, purpose, and system connections. This prevents sprawl and provides visibility across the entire fleet.
To manage shared resource limits, use centralised limiters like token buckets to allocate rate budgets before agents make model calls. Implement exponential backoff to prevent simultaneous reconnections, and add circuit breakers to external dependencies like LLM providers and tool endpoints to avoid cascading failures during service disruptions.
Lastly, optimise costs with smart task routing. Not every task requires the most advanced (and expensive) model. Route simpler tasks to cost-efficient models and reserve complex reasoning for high-performing ones. This strategy can cut model expenses by 40–60% without sacrificing quality.
For organisations looking to scale AI infrastructure while avoiding these pitfalls, Digital Fractal Technologies Inc offers AI consulting and custom development services. Their expertise in workflow automation and scalable system design can help ensure your agentic AI projects succeed where many others falter.
Comparison Table: Common Problems vs. Solutions vs. Expected Outcomes
Here’s a breakdown of common challenges, actionable solutions, and the tangible outcomes they can deliver during deployments.
| Problem | Solution | Expected Outcome |
|---|---|---|
| Misaligned Business Goals | Define clear KPIs and connect agents to measurable business metrics | Scaling success rate improves by 3x when production constraints are addressed from the start |
| Weak Governance and Security | Develop centralised governance frameworks and maintain agent registries | Error amplification drops significantly – from 17.2x with siloed agents to 4.4x with coordinated systems |
| Data Silos and Integration Failures | Adopt unified integration protocols like MCP | Integration time reduces from weeks to days per agent; development time cut by 30–40% |
| Over-Customization and Poor Scalability | Leverage standardised platforms, reusable templates, and validation layers | Malformed responses drop by over 95%; refactoring efforts decrease by 50–70% |
| Infrastructure Limits and Coordination Failures | Use work queue architecture, tiered model routing, and centralised rate limiting | Model costs drop by 40–60%; latency improves from ~6 seconds to ~2 seconds |
The solutions above often work together. For instance, addressing data silos not only speeds up integration but also strengthens governance. Similarly, using standardised agents reduces strain on infrastructure, creating a ripple effect across operations. These combined improvements directly tackle inefficiencies, driving faster and more effective scaling.
A real-world example highlights this approach in action. In 2025, a professional services firm with 120 employees implemented these strategies. They began with a client intake agent that saved 25 hours of partner time each week and generated an additional CA$40,000 in monthly pipeline revenue. Before scaling further, the firm spent two months building a shared platform with unified client data models and reusable connectors. This groundwork enabled them to roll out five coordinated agents within a year, achieving CA$520,000 in operational savings and revenue from an investment of CA$180,000 – a return of 2.9x. This case underscores how integrated solutions can lead to scalable, impactful AI deployments.
Conclusion
Scaling AI agents isn’t just a tech challenge – it’s about aligning strategy with execution. Moving from pilot projects to full-scale deployment requires a clear focus on measurable business outcomes, setting up governance frameworks early, and building infrastructure capable of handling complex, real-world scenarios. As Eric Jesse from BCG explains:
Devote 10% of their efforts to algorithms and 20% to technology and data; the remaining 70% of their efforts should focus on people and processes to make sure that the changes stick.
While 78% of enterprises are running AI agent pilots, only 14% manage to scale them successfully. Why? A staggering 89% of failures are tied to organizational hurdles like unclear ownership, integration in legacy systems, and insufficient monitoring systems. Success comes to those who design for production from the outset, invest in shared data systems early, and establish dedicated AI operations teams to oversee the entire lifecycle.
Tackling these challenges often creates a ripple effect. Breaking down data silos not only speeds up integration but also strengthens governance. Standardized platforms ease infrastructure demands and reduce the need for expensive rework. Building evaluation and monitoring systems in advance helps catch quality issues before they affect users. Together, these efforts lay a solid foundation for scalable success.
Expert guidance can make all the difference. Digital Fractal Technologies Inc offers specialized support to help businesses establish the critical evaluation, monitoring, and integration systems needed for dependable AI deployment. Their expertise in AI consulting, workflow automation, and custom software development empowers organizations to move past the experimental phase and achieve measurable outcomes – whether it’s cutting infrastructure costs, streamlining transactions, or driving ROI from AI investments.
The way forward is straightforward: start with a focused strategy, build a strong platform, assign clear responsibilities, and scale step by step.
FAQs
Which AI agent use case should we scale first?
Start with use cases that demonstrate clear benefits and are manageable to scale. A good starting point could be automating repetitive tasks, like deploying customer service chatbots or streamlining basic process automation. These types of projects are typically simpler to implement, easier to monitor, and can be scaled step by step.
To set the stage for success, focus on getting your organization ready. This means defining clear ownership, establishing governance structures, and creating processes to tackle potential challenges. By doing so, you’ll create a solid framework that supports future AI initiatives.
What governance controls must an AI agent have before it can take actions?
AI agents need governance controls, such as policy-based access control (PBAC), to restrict their autonomy while they operate. Beyond that, it’s crucial to have tools in place to monitor, audit, and interpret their actions in real-time. These measures help ensure the agent’s behaviour aligns with safety and compliance standards.
How can siloed data be unified for real-time AI agents without extensive rework?
Unifying siloed data without overhauling existing systems can be achieved by implementing an AI-native data layer. This approach standardizes and integrates data from platforms like CRM or ERP, ensuring AI agents have access to consistent and up-to-date information.
In addition, using event-driven architectures and data streaming facilitates continuous synchronization. This not only simplifies the process but also keeps costs manageable while enabling scalable, real-time AI operations.

